An unexplainable, computationally-costly, buzz-algorithm*** no-one needs.
Ok, maybe this is a little strong, but I have rolled my eyes at enough papers that I think I need to say some things about Shapley values. If you haven’t been paying attention (and for a few years, I wasn’t), SHAP — a particular form of Shapley values — has become a go-to method for explaining the predictions that result from Machine Learning methods. While I appreciate the motivations of the original paper, I think that they are a sub-optimal choice for this purpose. They are also about the most computationally-intensive choice that you could design as well. It’s therefore somewhat mysterious that they keep being used.
I put this down to over-indexing on axiomatization: Shapley values uniquely satisfy a set of desiderata, and this mathiness of their formulation blinds otherwise-sensible computer scientists to the question of whether they are actually helpful. This is not dissimilar in the way in which blockchain algorithms purport to provide anonymity as well as security, leading to their adoption even when they might not be the optimal solution, hence my title. The two also share the trait of not being readily explainable, or often explained, to outsiders.
In fact, SHAP encompasses two ideas: Shapley values as a general method of valuing members of a set, and the particular way that they are used to produce explanations. I think both the general application of Shapley values to xAI, and the particular choices of the SHAP methodology are problematic. I’ll try to explain both fairly, along with my critiques below.
Shapley Values
Shapley values are a long-standing (dating to 1953) idea about assigning values to a member of a coalition. Shapley values are explained in lots of places (wikipedia is my first go-to) but I want to start by motivating their use from the point of view of one particular problem in machine learning diagnostics (and not the problem that SHAP looks at).
How do we assign a value to an input feature? We might want to do this for screening purposes, or to prioritize features for additional investigation, or maybe just to give ourselves a sense of control. A really easy to metric is to say,
What if learned  with all the features, and
with all the features, and 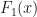 with everything except
with everything except 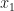 ?.
?.
We might then look at the change in predictive ability when you remove from the data set: 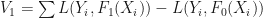 . That is, how much does my error rate increase when I remove and learn at new
. That is, how much does my error rate increase when I remove and learn at new 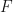 without it?
without it?
This is, in fact, a very reasonable (and common) thing to do, but you do need to worry about the following: what if and  are nearly interchangeable? Maybe one measures my height and the other is my trouser inseam. I can predict one from the other nearly perfectly, which means that if I remove height from the model to get can use inseam to compensate and do nearly as well, and vice versa. That means that neither nor will look important under this metric, even if removing both would be very harmful.
are nearly interchangeable? Maybe one measures my height and the other is my trouser inseam. I can predict one from the other nearly perfectly, which means that if I remove height from the model to get can use inseam to compensate and do nearly as well, and vice versa. That means that neither nor will look important under this metric, even if removing both would be very harmful.
You can also come up with the reverse situation: might not be very helpful unless we also know : to predict obesity I need both height and weight, one by itself isn’t very useful.
So how to deal with this? What I need to do is to look not just at dropping single features, but also dropping pairs, and triples, and so forth. This is where Shapley values come in. Specifically Shapley values are calculated the following way ****:
- put the features in some order (not the ordering they came in)
- going along the order, learn a model using the features up until each position in the order
- is given a value corresponding to the change in error when it is added to those features that came before it
- now average the values over all possible ways of ordering the features (in practice, choose a set of orderings at random) to give Shapley value
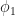 .
.
Here sometimes height will come up before inseam and will make a big difference to predictive skill, sometimes it will come up afterwards and will make very little difference (but inseam will make a big difference), and these two will get averaged out over orderings. Note that there is a lot of computing work to do here, hence the need to just look at a random sample of orderings (and even then it’s a lot of work).
Why is this the right thing to do? (Note that it’s different to averaging out over the possible set of features that might have come before). This was derived by Lloyd Shapley in a paper in 1953 for a more general problem in valuing coalitions. Here we suppose we have players  and can produce a value
and can produce a value 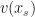 for any subset
for any subset  of the players and we want to find a way of working out a value
of the players and we want to find a way of working out a value 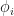 for each individual player
for each individual player 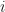 *****. This maps directly onto the problem above:
*****. This maps directly onto the problem above:  being the error rate for a model learned only with
being the error rate for a model learned only with 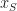 .
.
Shapley wrote down a series of reasonable desiderata for any such individual value and demonstrated that the calculation above is the only way of satisfying these. Indeed, Shapley values are mostly motivated by starting from a set of axioms that the should satisfy, which I suspect contributes to their mathematical dazzle.
As a general proposition, why am I unexcited by this? Firstly because I don’t think it’s very much more illuminating than the value you get for What happens if you drop ?, it’s just different. In fact, it tends to smooth out importance, making differences in importance between features look smaller. What it doesn’t tell you is relationships between features: We need or but not both. or doesn’t add much unless you also have .. The worst part about this is that you could get that information out of the calculation to get Shapley values, but it gets thrown away!
Secondly, however motivated, Shapley values dictate how you weight the improvement from adding by the size of the feature set you add it to. Frankly, I don’t care in the slightest what happens when you add to a model that only uses and a lot more about what happens when you at to a model that uses most of the features. Shapley upweights the effects for both very small and very large feature sets, while I might want to just look at the latter.
What about SHAP in particular?
Shapley values as used in Machine Learning make particular choices about the value function to use. In particular, rather than looking at what contributes to predictive accuracy, SHAP is based around explaining individual predictions. How is this done? SHAP looks at the prediction that would have been made if we only knew , which they calculate from 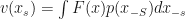 which integrates out all the features not in the set . Various choices can be made about what distribution to use, but I’d argue the only really sensible one is the conditional
which integrates out all the features not in the set . Various choices can be made about what distribution to use, but I’d argue the only really sensible one is the conditional 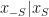 .
.
So what does the Shapley value for represent? It’s how much you change your prediction by being told the value of , averaged over the set of possible features whose values you might already know.
Well that sounds ok! Why don’t you like it (beyond the objections above)? My answer here is What am I now supposed to do? First of all, I already know ! So telling me what that information changed is pretty artificial. I might want to know how sensitive  is to the value of (eg, it tells me how to change the prediction most quickly), but that looks more like LIME. And if you want to explain it to a lay-person we’re talking in pretty abstract terms.
is to the value of (eg, it tells me how to change the prediction most quickly), but that looks more like LIME. And if you want to explain it to a lay-person we’re talking in pretty abstract terms.
I think this particular choice of value function was motivated by one of the core Shapley desiderata: the values of all the Shapley values, should add up to the value for the full set 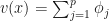 . So here we are breaking out
. So here we are breaking out  into a sum of contributions, one from each feature. There’s some appeal here, but note that this is not a representation as an additive model — each of the
into a sum of contributions, one from each feature. There’s some appeal here, but note that this is not a representation as an additive model — each of the 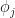 is itself a rather complex function of all the features. To be actually fair, we should write
is itself a rather complex function of all the features. To be actually fair, we should write 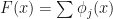
Add to this the computational effort in first, evaluating the integral to calculate and second, looking over a set a orderings (and that’s without ensuring that you get stable answers) and you end up with a number that is
- Difficult to explain without a lot of technical terminology
- More computationally costly than just about any alternative
- Frequently mistaken for meaning something that it doesn’t
The perfect analogue of blockchain!
And just like blockchain, there are some legitimate uses — in this case mostly in aggregating up to something that looks more like global values — but this is far narrower than the way it is currently used.
And what about those axioms?
Shapley values get a lot of their appeal by satisfying a set of desiderata, and I guess I should nominate what I think is irrelevant. The four criteria (expressed as values for features) are:
- null sets: if a feature adds nothing in addition to any set of features already in the model, it gets Shapley value 0
- additivity: the Shapley values for the sum of two value functions is the sum of the Shapley values
- symmetry: if
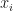 always contributes the same as
always contributes the same as 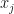 to any coalition, they have the same Shapley value
to any coalition, they have the same Shapley value
- efficiency: the Shapley values add up to the value of the whole set.
The first two of these are very reasonable, and by and large the third is, too. But I see no reason that the fourth needs to hold, either for global explanations or to explain particular predictions. It’s fine to have an importance measure that describes changes to a function rather than its whole value! (If a value function is even the right way to think about this.) Unfortunately, unlike the first three desiderata where removing them has interesting effects, removing the last rather creates open slather: we need to think again about what we want an explanation to mean, and usually for what purpose.
*** buzzgorithm?
**** I’m deliberately presenting the calculation first, then the justification because I want to understand if something is helpful before being blinded by the axioms
***** The motivation is sometimes that we value players in a sport team, but then small coalitions don’t make a lot of sense. Political coalitions may be a bit more helpful.
 . That is, we could not say that the bias in our models was small enough to ignore when performing inference. What were we really learning if we couldn’t relate what we got to real-world quantities?
. That is, we could not say that the bias in our models was small enough to ignore when performing inference. What were we really learning if we couldn’t relate what we got to real-world quantities?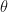 and data
and data 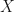 are given by
are given by ![I(X) = [\hat{\theta}(X)-l,\hat{\theta}(X)+u]](https://s0.wp.com/latex.php?latex=I%28X%29+%3D+%5B%5Chat%7B%5Ctheta%7D%28X%29-l%2C%5Chat%7B%5Ctheta%7D%28X%29%2Bu%5D&bg=ffffff&fg=111111&s=0&c=20201002) where
where 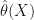 calculates an estimator for an unknown
calculates an estimator for an unknown 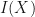 includes
includes 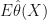 95% of the time.
95% of the time. so that
so that 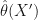 is in
is in 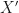 is an new set of data independent of
is an new set of data independent of 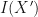 — you do have to take a distribution over both
— you do have to take a distribution over both 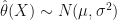 then
then 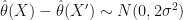
 — these are simply
— these are simply 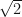 times as large as standard confidence intervals.
times as large as standard confidence intervals.
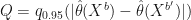 , and form
, and form 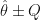 .
.
