As usual, my blogging is like my personal correspondence — far too infrequent for my mental health or my audience’s engagement. For anyone still out there, thank you for following!
This is a quick exploration of exactly what uncertainty quantification in machine learning should look like. When Lucas Mentch and I first developed uncertainty quantification methods for random forests; , one thing that we had real difficulty with was the fact that our theoretical results guaranteed that confidence intervals would cover the expectation of the predictions of an RF, rather than some underlying truth such as 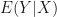
I always justified this by saying that our results were really interested in using the ensemble structure in random forests to develop theory. (And indeed this was/is true!) If you want to control bias, you need to analyze the ensemble members very carefully. That’s just what Susan Athey and Stefan Wager did in their seminal CLT paper, with some very nice mathematical arguments.
But to be honest, even if you use the sort of mechanisms that Wager and Athey advocate, it’s not hard to find bias in simulation. Under the right conditions it might disappear asympoticaly, but in finite samples you might still be getting the wrong answer. This is, frankly, true of just about any ML method you care to use, and most more classical nonparametric smoothing methods as well (that is, you can undersmooth to avoid bias, but in practice the finite sample statistical properties are still not great).
Now I still think that there is some utility in providing uncertainty quantification, even if it isn’t in the form of formalized inference. However, we do need to distinguish what it is that an uncertainty interval is trying to capture. For this, I really like the idea of reproduction intervals that student Yichen Zhou came up with. Indeed, they seem so natural that it has taken me up until now to realize that they really require some publicity. So far, we’ve only discussed them in the simulation section of this paper.
The idea can be captured rather simply. Traditional confidence intervals for some parameter 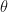
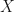
![I(X) = [\hat{\theta}(X)-l,\hat{\theta}(X)+u]](https://s0.wp.com/latex.php?latex=I%28X%29+%3D+%5B%5Chat%7B%5Ctheta%7D%28X%29-l%2C%5Chat%7B%5Ctheta%7D%28X%29%2Bu%5D&bg=ffffff&fg=111111&s=0&c=20201002)
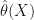
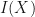
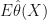
What Yichen suggested is to avoid asking about covering an underlying truth. Instead, we just want to know How different might your answer be with new data. That is, we want 
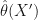
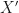
- It makes explicit that we are interested in stability rather than inference. The term reproduction interval comes from asking about reproducing an estimate with new data.
- While it doesn’t quite do away with the mental effort of imagining a universe of alternative data sets, it does feel more natural. It’s not quite right to say that for this particular
— you do have to take a distribution over both
- It’s computationally no harder than standard confidence intervals. The ideas in the Boulevard paper were based around an asymptotic normal result where if we have that
then
and 95% reproduction intervals are given by— these are simply
times as large as standard confidence intervals.
It’s also pretty easy to provide bootstrap intervals. These are always symmetric because of the symmetry between
, and form
.
The ideas were started from work in this paper where we asked about how large a data set we would need to consistently select the same split when building a decision tree (in our case we were generating the data, so this was possible), which we cast as a power calculation problem. There we really were asking about “What would happen with a new data set?”, but that turns pretty naturally into confidence intervals.
Now I wouldn’t want to claim this is all we should do. Bias matters for inference in lots of situations, and providing genuine confidence intervals is important. However, I do think that these at least provide some useful information, particularly in areas like machine learning. One might think of them as fitting neatly into Bin Yu’s PCS framework. Possibly (probably?) they should be thought of as a second-best option, but you could make a case that all our models are biassed anyway and this is just being honest.
Now the question is how one publicizes/advocates for it. It really is simple so would be surprised if it isn’t already in the literature. I’m very willing to give credit elsewhere if provided with a pointer, but whoever should take credit, I still need a way to say “This is a good idea, you should do it”.